Modeling(데이터베이스 모델링)
1장
업무 파악 > 개념적 데이터 모델링(erd diagram) > 논리적 데이터 모델링(표) > 물리적 데이터 모델링(sql 코드)
2장
업무파악 - 의뢰한 사람과 ui 그려보기(기획서 제작)
3장


4장
개념적 데이터 모델링: 연관된 정보를 그룹화하여 그룹끼리의 관계를 표현한다.

5장


원하는 데이터만을 join하기에 쉽다.
6장



'글'에 '저자'를 속성으로 넣지 않는 이유는, '저자'만의 '저자 소개','저자 가입일' 등의 속성을 가지기 때문이다.
PK, FK로 관계를 가지게된 테이블들은 JOIN을 통해 연결할 수 있게 된다.
7장, 8장
식별자 선택: PK 선택



9장

10장
cardinality: 1:1, N:1, N:M


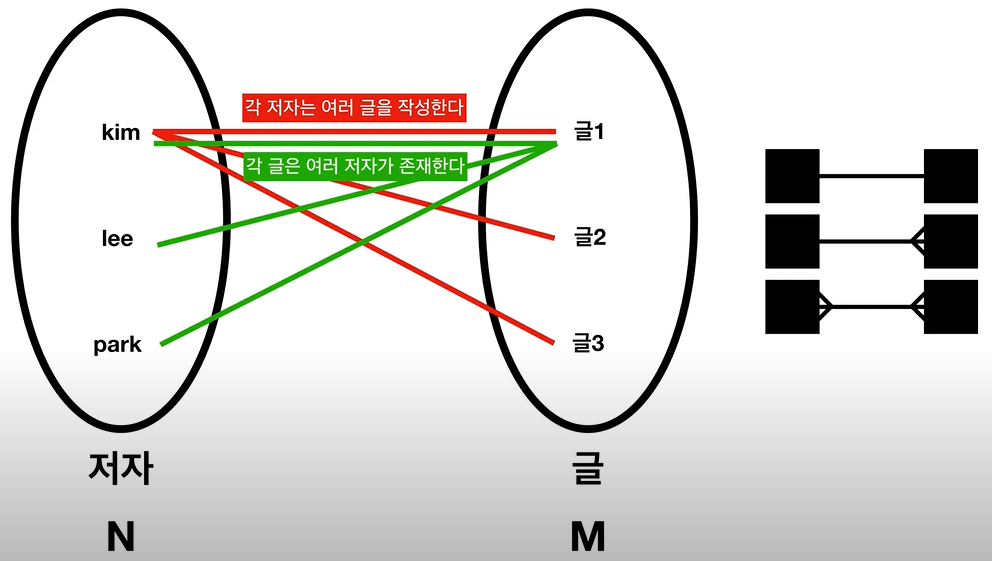
하지만, 에브리 타임 앱에서, '작성'이라는 관계로 묶여있는 저자와 글은 1:N으로 설정해야 한다.
11장
optionality: 필수와 선택


12장

13장
논리적 데이터 모델링: mapping rule

14장
1:1
기본키와 연결된 외래키는 타입이 같아야 한다.


15장
1:N

16장
N:M - 어느 테이블에 JOIN을 해야하는지 애매해서 문제 -> 연결 테이블이 필요



17장: 정규화

18장: 제1 정규화(각 칼럼의 값들이 atomic 해야한다)
- 하늘색 부분에 대한 문제와 해결
SELECT * FROM topic WHERE tag='free',
SELECT * FROM topic ORDER BY tag
같은 명령어를 쓸 수 없다.

19장: 제2 정규화(부분 종속성을 없애야 한다 if 중복키가 있다면)
- 핑크색 부분에 대한 문제와 해결(중복되는 값)


20장: 제3 정규화(이행적 종속성을 만족시켜야 한다)

중복되는게 문제다. 테이블을 따로 빼보자.

회고
- 에브리타임은 user와 post관계가 1:n이다. '작성'이라는 관계로 묶여있기 때문이다.
- 속성으로 배열을 넣으면 안된다. 정렬에 문제가 생겨 정보가 누락되기 때문이다. ex. where문, order by문, join문 => 테이블 분리 by 제1 정규화 법칙
- n:m 관계는 연결 테이블을 만들어 1:n, 1:n으로 이어 해결한다. (단, 연결테이블을 만들 때는 중복될 수 있는 값을 고려해 기본키를 잘 설정해야한다.) ex. user table - write table - post table
- 정규화를 통해 잘 쪼개진 테이블은 읽기 기능을 희생시켜 쓰기 기능을 올린 것이다. join연산은 비싸기 때문이다. 그렇다고 정규화가 성능을 떨어뜨린다는 것은 아니다.
- 따라서, 인덱싱이나 캐시 기법을 쓰고도 데이터베이스의 느림이 인지된다면, 역정규화(테이블 수정)을 거친다.